
Had written a tweet storm(Linked below) on this topic earlier, this blog a longer version of the same and addresses some questions people raised
One problem that stumps many new PMs is measuring the impact of small features.
Eg: how do you justify any changes to orders screen, or making slight changes to the text in some obscure corner of product, or just informational changes .
What if you added small delight features like a fancy error message or a funny wait timer.

While you would LOVE to A/B test everything and see if these changes are positively affecting the core metric, unless you have a large number of users hitting those scenarios, you would not be able to get meaningful stats sig results.
Companies with billions of users can test even the minutest of things, eg Google allegedly tested 41 shades of blue , and Uber can test its custom fonts, but it’s unlikely that many companies will have the scale necessary to observe a stats sig result.

So how do you make a case for making those changes and if you do that, how do you measure these.
One way of course is to simply not measure the success (Or measure but do not expect). Think of these as paper cuts, its annoying but one won’t really kill you. The idea is that you go with what you deem is right and not get into analysis paralysis mode. You see a paper cut and fix it.
But relying too much on gut as two major disadvantages
- Experience: Unfortunately developing a good “gut reaction” is a tricky problem and requires a lot of past experience to rely on. “Gut” is but a culmination of lot of data you have already seen
- What is not measured is not rewarded: Unless you are running your own startup or have significant stake in one, you want to make sure you get recognised and rewarded for your work. If there is no way to measure something, there is no real way to recognise and reward it. All it may get you is a pat on the back . It is also deeply unsatisfying because you have NO idea if you are actually adding value
One simple way of measuring these changes is “constant holdback”
Whenever you roll out such an experiment, instead of rolling it out to 100% of users, roll it out to only 95% of your users. Do the same for all other small changes, with the same 5% always excluded.
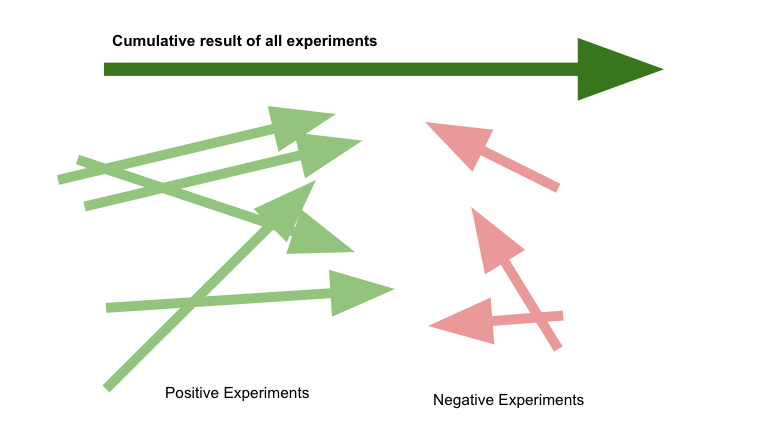
As experiments pile up, the effect of multiple paper cuts being fixed would start showing up .
You would potentially be able to see the holdback group having meaningfully different(worse) metrics than the rest of the group..
But how do you know which experiment worked:
That is the point, you potentially will not. You will see cumulative effects and not specific.
What if some experiments are actually harmful
The idea is not to have all super positive experiments but to know if you have been directionally right. The trick is to pick mundane obvious changes that you need to do rather than using this for large features. If you are directionally right, you could eventually see a nice bump.
Can I do this for large new features
If you can do control vs treatment A/B test for any feature I would advise you to not use this holdback method as the primary means of testing. You do not want to have large experiments in the mix that can completely change the general direction of overall result
But I would argue that this hold back is useful even for large experiments once you have tested them . Post your A/B experiment you can think about a holdback for large features as well. The reason is that not all changes are plain additive. Eg: If you see your conversions go up by 2% via one feature and 3% via another, on long term its not necessary that overall it would be 5% . A constant holdback would tell you the cumulative effect of all the large changes you may have done
Do not forget to delete the holdback eventually so that all your users can see the same improved experience.
Leave a Reply